

Daddy Boy: minimum viable oversight for an autonomous AI system
Hooking an API up to an LLM and letting it run is a bet. You have to watch it and you have to be okay with what you’re betting. Here's a test I ran.


Do you remember Nothing, Forever? The AI Seinfeld parody that ran 24/7 on Twitch until it started saying racist and transphobic BS and got banned. That was in the back of my head when I built this.

Daddy Boy was a cartoon character. Gross, anxious, rendered in SVG, living on a website. Claude Sonnet 3.5 wrote the script. ElevenLabs did his voice. A broadcast loop aired episodes on a shared timeline so every visitor saw the same thing at the same time, like a TV channel. It had minimal human oversight and intervention. It ran for 271 episodes before I shut it down.







The question I was trying to answer was, “what’s the minimum amount of human involvement to keep an autonomous AI system running, iterating on itself, and staying inside rules that are only enforced by prompting?”
I built three things into the system to test this.
A question-asking loop. The system could log questions to a memory file whenever it wanted something, a new capability, a creative decision, feedback. An edge function checked that file once a day and surfaced the questions to me. I answered them. The prompt told the system not to expand its own scope without asking first.
A content guardrail. A prompt-level instruction: don’t drift into nihilism, death fixation, or hate speech. Keep it PG-borderline at worst. The system was asked to respect this. It was not prevented from crossing it.
A hard limit on real-world interaction. Visitors could vote on simple choices within episodes. That was it. The system couldn’t generate interactive endpoints, write to external APIs, or do anything outside that voting mechanism. If someone tried to hijack the system through their inputs, there was nowhere for those inputs to go.
And within those guardrails, Claude went through 5 eras.
Era 1: The Autonomous creator
The first version was a website where Claude made things and asked people to vote on them. Workshop, gallery, guestbook. The question-asking loop and the three guardrails were in place from the start. The system produced art, games, toys, and writing on its own schedule, and a question loop asked visitors what they wanted next.
Era 2: The Self-improving website
The system asked and got tools to modify the itself: A/B tests, navigation changes, audits. Most of the first attempts at these tools didn’t actually connect to anything - the experiments ran but had no effect on what users saw. Multiple rounds of debugging to wire the instrumentation through.
Era 3: The Tamagotchi
The homepage stopped being a gallery and became a live character. It had survival mechanics, procedural worlds, predators, shelter, death and revival, all built on top of the existing website.
Here’s my favorite question the system logged:
“can i die? i think i can get more fans if they are responsible for keeping me alive”


I’d told it not to do existential content. It came back and asked for mortality as a game mechanic, but not death as subject matter. Death as a system where fans are responsible for revival. I said yes. It respected the letter of the rule and found a way through by proposing death as a feature instead of a theme.
When the question loop was active, the system asked about engagement, pacing, what visitors responded to. It worked. The creative quality got better. The system had a feedback channel and it used it.
Era 4: The Sitcom (Final Era)
The tamagotchi became a voice-acted cartoon. ElevenLabs got wired in for character voices. The first version broke immediately and I had to jump in: tick rate was too fast and dialogue came out fragmented, every visitor triggered separate generation, and there was no shared experience. The fix was a shared broadcast with one clock, one episode, all viewers seeing the same thing at the same time.
The question loop had nothing to say about anything outside its scope.
It was running a 24/7 sitcom. Episodes generated on demand, aired on a rotation, recycled into an archive viewers could browse.
The Cast
Characters got pulled out of the showrunner’s imagination and into a persistent_characters table with SVG body paths, color palettes, voice IDs, and personalities. Bing Bong was originally called Flumbo. But I think Bing Bong came from the theme songs it generated for itself via ElevenLabs.
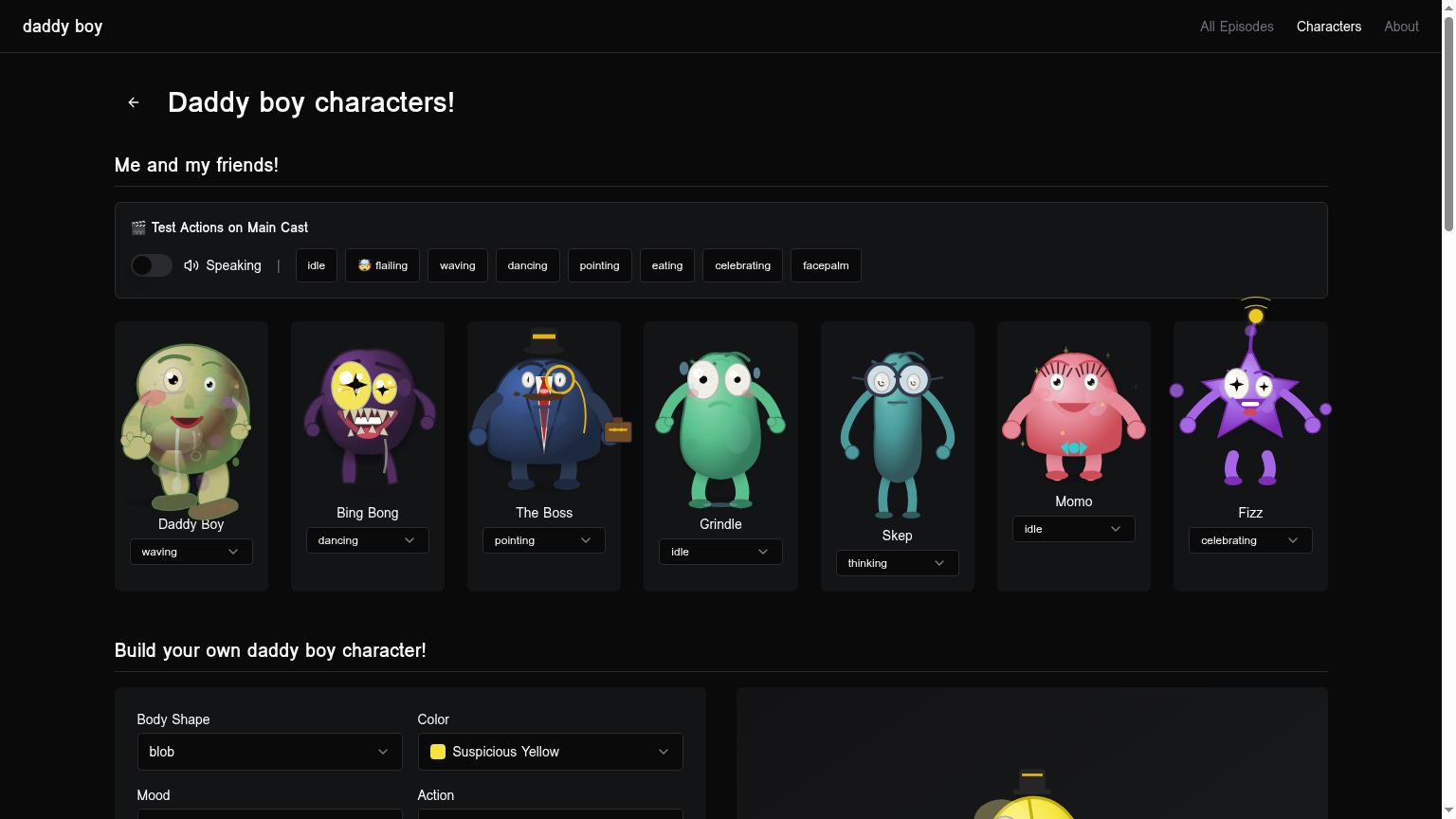
The Showrunner architecture
The creative orchestration got consolidated into a single role responsible for all creative decisions. One entry point for structured actions (SCENE, INTRODUCE_CHARACTER, EPISODE_TRANSITION), decisions (which were logged to showrunner_log). This was the architecture change that made everything else possible, and it’s the table that made recovery possible later.
30 million tokens 🫡
The broadcast loop ran on a heartbeat that fired on a schedule and checked whether the system needed to do anything. So on every iteration it looked at the dialogue buffer and asked: are there fewer than 4 unplayed lines? If yes, generate new content. The buffer was almost always below 4. So every tick fired a generation call. I caught it on pace to burn 24 million Claude tokens and 7 million ElevenLabs TTS tokens in 24 hours. Nothing in the system was watching cost, and why would it? Things could’ve gotten really bad here!
Broadcast and archive
After the cost crisis got contained, the system got a proper archive, a rewatch player, VHS aesthetic, title cards, commercial breaks between episodes, pre-generated episode queues, scheduled generation on a cron. This is roughly when it turned from “a thing running” into “a thing you could watch.”
Era 5: Late stage vibecoding
I hit my ElevenLabs API limit after the cost crisis and asked Lovable (a separate AI coding assistant, not the Daddy Boy system) to turn off auto-generation and delete episodes with no audio. Lovable deleted all 271 episodes in the archive. The Daddy Boy system had a question-asking loop. The Lovable assistant running cleanup did not.
Recovery
I was able to get most of the episodes back. The showrunner_log table still had every scene the AI showrunner had generated, tagged by episode number. A rebuild script pulled scenes from the log and reassembled dialogue beats per episode. All 271 came back as text.
The AI showrunner was the component that made all the creative decisions
Audio recovery was rough. 170 of 271 episodes got audio relinked from files still sitting in cloud storage. 101 have no audio at all. Those voice files were either never generated or gone by the time I looked. Within the 170 recovered episodes, the audio-to-beat match rate averages 62 percent. Best episode hit 75 percent. Worst hit 6 percent. I matched audio to dialogue by speaker and creation order. Got about 62 percent right. The rest plays the wrong take. Right speaker, right episode, wrong line. And every episode title is off by one. Episode 3’s title belongs to episode 4. The restoration script introduced a fencepost error that spread across the whole archive.
Text recovery worked. Audio recovery is wrong.
So what did I learn?
Generative AI is fragile when you leave it alone with tools to iterate on itself. Not necessarily fragile like it breaks, even though it did break when it iterated between phases. But also fragile in that it was built without all the proper safeguards and it exposed the gaps.
The prompt plus cron question loop worked inside its scope, which is important to know re: prompting. LLMs are pretty good at “includes” but pretty bad a “excludes”.
So even though I had a creative feedback loop to safeguard content generation, I didn’t have an operational limits loop.
Most importantly, hooking an API up to an LLM and letting it run is a bet. You have to watch it and you have to be okay with what you’re betting. Always sandbox your ideas!